Last updated on May 10, 2026
A 3-Part Series: Agents, Workflows, and Skills – Build the Right Thing
In Part 1, we built a bug investigation agent. In Part 2, we built a content quality pipeline. Both worked. Both had AI doing something I hope you find genuinely useful. But if you read them back to back with a sufficiently critical eye – the kind of eye a good code reviewer develops after seeing the same mistake for the fifth time – you’d notice something I deliberately left in both systems: capability reuse.
The bug agent could search code. The content pipeline had its own policy checker. Each of those capabilities lived inline, coupled to the specific system that needed it. The policy checking logic in the pipeline was not the same code as the policy checking logic you’d write for, say, a customer support ticket triage system. But it could be. It’s the same operation. Without a critical eyes, it runs the risk of being written twice – or more likely, written twice slightly differently, tested separately, and now drifting apart in ways nobody is tracking.
I’ve seen this pattern play out through out my career. At inexperience hands, 3 AI-powered features built over time. Each one has its own summarizer, its own classifier, its own retry logic, its own JSON parsing. When a model gets updated and the JSON format changes slightly, someone spends a week hunting down every place they were parsing model output. When they want to improve the summarization quality, they improve it in one place and forget about the other two.
This is the skills problem. It’s not technically hard. It’s architecturally unglamorous. Nobody gives conference talks about their skill library. But I will tell you with the confidence of someone who has built many large platforms for several years now: the teams with clean libraries move twice as fast and debug half as often as the teams without one – skills are no different.
What is a Skill?
A skill is a self-contained, reusable capability that can be invoked by an agent as a tool, called as a step in a workflow, or used standalone. It’s the atomic unit of AI behavior in your system.
A skill has:
- A single, clear purpose – it does one thing, well, and only that thing
- A defined interface – typed inputs, typed outputs; the contract is the API
- Encapsulated intelligence – the prompt, the retry logic, the output parsing all live inside, hidden from the caller
- Independently testable behavior – you can write a test for it without standing up the surrounding system
Think of a skill like a well-designed library function. Except instead of pure computation, it might call a language model internally. The caller doesn’t need to know which – they just call it and get back a typed result.
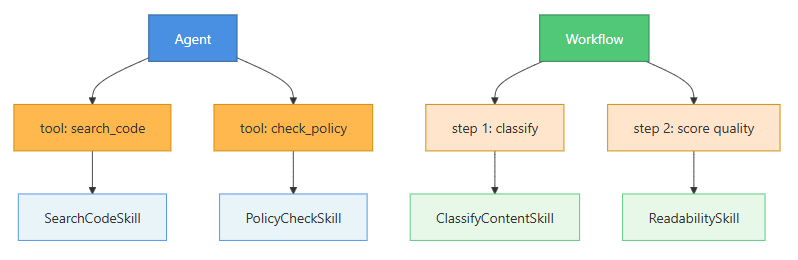
Example code from Part 1 and Part 2 does not overlap. However, if it had, the same skill could be called by multiple callers. One implementation, one test suite, one prompt to maintain.
Skills vs. Tools vs. Steps: The Confusion Is Real
I’ve sat in too many architecture reviews where these three words were used interchangeably. They’re not the same thing, and the distinction matters:
| Concept | Where it lives | Who calls it | What it actually is |
|---|---|---|---|
| Tool | Agent’s tool schema | The model (via tool_use) | An interface declaration |
| Step | Workflow orchestrator | The workflow code | A role in a pipeline |
| Skill | Your shared library | Tools AND steps – anything | The reusable implementation |
Here’s the mental model: a tool is the job posting. A step is the org chart position. A skill is the actual human being (or in our case, the code) that can fill either role.
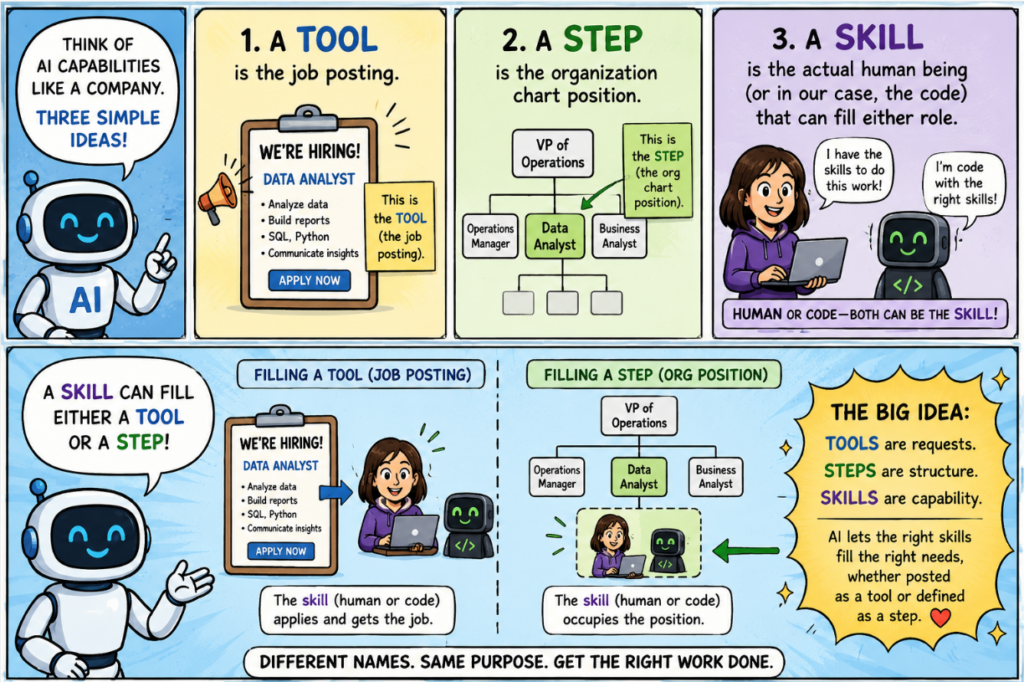
When you build skills correctly, your tool declarations become thin wrappers around skill calls, and your workflow steps become 1-liners. The intelligence moves down into the skill layer, where it can be tested and shared.
When to Build a Skill
The Rule of Two-and-a-Half
You’ve probably heard of the Rule of Three: when you write the same thing three times, abstract it. That’s fine advice for regular code. For AI capabilities, I prefer to be more aggressive – I call it the Rule of Two-and-a-Half:
- Once: Write it inline. No abstraction needed.
- Twice: Write it inline, but leave a comment:
// TODO: extract when this appears a third time - Two-and-a-half times: The half is when you know a third use is coming – like when someone says “hey, can we add this same check to the onboarding flow?” Extract it now, before the third inline copy gets written.
Other signals that it’s time to extract a skill:
- The capability has testable behavior with a clear pass/fail
- The AI prompt is getting long and deserves to be documented properly
- The retry logic or output parsing is non-trivial
- You want to change the underlying model for this specific capability without touching six other things
Don’t over-engineer it. If something is genuinely used in exactly one place and you can’t imagine that changing, leave it inline. Shared infrastructure for its own sake is friction without payoff. Abstract when you feel the pain of not abstracting – not in anticipation of hypothetical reuse.
The pull toward over-engineering rarely announces itself. It shows up quietly, disguised as good judgment. You convince yourself you’re being thorough, responsible – even clever. Even with my experiences, I still have to stop and ask: is this actually needed, or am I drifting into “you aren’t gonna need it” territory?
What Makes a Good Skill: 5 Rules I Learned the Hard Way
1. One responsibility, enforced aggressively.
I once reviewed a skill called analyze_and_recommend_classification. It summarized logical model defined in excel sheet, classified them, and checked them for policy violations. Three distinct operations, one class, zero reusability. When the summarization prompt needed improving, you had to understand the entire class to make the change safely.
Split it. Always. The composition is the caller’s job, not the skill’s.
2. The typed contract is the public API.
The input and output types are not implementation details – they’re the interface. Treat changes to them like you’d treat breaking changes to a REST API: with changelog entries and version bumps and advance notice to callers. I’ve seen skills where the output was a raw string and the caller parsed it however they wanted. When the prompt format changed, 3 callers broke silently. Types prevent this.
3. No ambient state.
A skill should not reach into global config, environment variables, or shared mutable state by default. Pass in what it needs. This isn’t just philosophical – skills that reach into global state are nearly impossible to unit test without mocking half your application. Skills that take explicit parameters are trivially testable. Choose your future.
4. The prompt is code.
The system prompt inside a skill is not a comment or documentation – it’s logic. It determines how the AI behaves. When you change it, you’re changing the behavior of every caller. Treat significant prompt changes like code changes: review them, test them (yes, with real model calls), and note them in your commit history.
5. Observable by default.
Log the token count, latency, and model used on every call. Not optionally. Always. Your future self will be debugging a production issue at a bad hour, and the difference between tokens=2400, latency=1200ms in the logs and nothing will be the difference between a 20-minute fix and a three-hour investigation.
Step-by-Step: Building a Skill Library
Let’s build the library. We’ll extract the capabilities from Parts 1 and 2 into reusable skills, then show how both the bug investigation agent and the content pipeline can use them – with substantially less code in each.
The same pom.xml from Part 1 applies here. Add the Jackson dependency if you’re not using spring-boot-starter-web (which already pulls it in):
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>Skills we’re building:
SummarizeSkill— summarize any text to a target lengthClassifySkill— classify text into one of N categoriesPolicyCheckSkill— check text against a configurable rule setExtractStructuredDataSkill— extract typed data from unstructured text
Step 1: Define the Skill Interface and Infrastructure
Start with the interface. Skill<T> is the contract every skill – atomic or composite – satisfies. Agents, workflows, and registries all depend on this interface, not on implementation classes.
// Skill.java — the public contract for every skill in the library
package me.johnra.tutorial.skills;
public interface Skill<T> {
String skillName();
SkillResult<T> run(String input);
}// SkillResult.java — carries the output plus observability metadata
package me.johnra.tutorial.skills;
public record SkillResult<T>(
T output,
String model,
int inputTokens,
int outputTokens,
long latencyMs,
String skillName
) {}Next, the JSON extraction utility. Models don’t always return clean JSON – they may wrap it in code fences, add explanatory prose, or emit <think> reasoning blocks before the answer (qwen3 does this; llama3.2 does not). This class handles all three cases in one place so no skill needs to manage it independently.
// JsonExtractor.java — normalises model output before JSON parsing
package me.johnra.tutorial.skills;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
final class JsonExtractor {
private static final Pattern FENCED = Pattern.compile("(?s)```[a-z]*\\n?(.*?)```");
private JsonExtractor() {}
static String extract(String text) {
String s = text.strip();
// Strip <think>...</think> reasoning blocks emitted by some models
s = s.replaceAll("(?s)<think>.*?</think>", "").strip();
// Extract content from the first fenced code block if present
Matcher fenced = FENCED.matcher(s);
if (fenced.find()) {
return fenced.group(1).strip();
}
// Fall back: extract the first {...} block, ignoring surrounding prose
int start = s.indexOf('{');
int end = s.lastIndexOf('}');
if (start != -1 && end > start) {
return s.substring(start, end + 1);
}
return s;
}
}Now the abstract base class. BaseSkill<T> implements Skill<T> – it provides the retry loop, token tracking, and structured logging that every concrete skill inherits. Note that chatModel is private: callers interact through the Skill<T> interface and have no reason to reach inside.
// BaseSkill.java — handles retry, timing, and logging so concrete skills don't have to
package me.johnra.tutorial.skills;
import dev.langchain4j.data.message.AiMessage;
import dev.langchain4j.data.message.ChatMessage;
import dev.langchain4j.data.message.SystemMessage;
import dev.langchain4j.data.message.UserMessage;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.output.Response;
import dev.langchain4j.model.output.TokenUsage;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.util.List;
public abstract class BaseSkill<T> implements Skill<T> {
protected final Logger log = LoggerFactory.getLogger(getClass());
private final ChatLanguageModel chatModel;
private final int maxRetries;
protected BaseSkill(ChatLanguageModel chatModel) {
this(chatModel, 3);
}
protected BaseSkill(ChatLanguageModel chatModel, int maxRetries) {
this.chatModel = chatModel;
this.maxRetries = maxRetries;
}
protected abstract String buildSystemPrompt();
protected abstract T parseResponse(String text) throws Exception;
@Override
public SkillResult<T> run(String input) {
Exception lastError = null;
long start = System.currentTimeMillis();
for (int attempt = 0; attempt < maxRetries; attempt++) {
try {
List<ChatMessage> messages = List.of(
SystemMessage.from(buildSystemPrompt()),
UserMessage.from(input));
Response<AiMessage> response = chatModel.generate(messages);
long latencyMs = System.currentTimeMillis() - start;
T output = parseResponse(response.content().text());
TokenUsage usage = response.tokenUsage();
int inputTokens = usage != null ? usage.inputTokenCount() : 0;
int outputTokens = usage != null ? usage.outputTokenCount() : 0;
log.info("[{}] success | tokens={}/{} | latency={}ms",
skillName(), inputTokens, outputTokens, latencyMs);
return new SkillResult<>(output, "ollama", inputTokens, outputTokens, latencyMs, skillName());
} catch (Exception e) {
lastError = e;
if (attempt < maxRetries - 1) {
long waitMs = (long) Math.pow(2, attempt) * 1000L;
log.warn("[{}] attempt {} failed, retrying in {}ms: {}",
skillName(), attempt + 1, waitMs, e.getMessage());
try {
Thread.sleep(waitMs);
} catch (InterruptedException ie) {
Thread.currentThread().interrupt();
}
}
}
}
throw new RuntimeException(
"[" + skillName() + "] failed after " + maxRetries + " attempts", lastError);
}
}Write these three files once. Never write retry logic, token logging, or JSON cleanup in a skill again.
Step 2: The ClassifySkill
Classification is one of the highest-ROI in this example AI application. It’s fast, it’s cheap (use a small model), and it removes an enormous amount of human triage overhead.
// ClassificationResult.java
package me.johnra.tutorial.skills;
public record ClassificationResult(
String category,
double confidence, // 0.0 to 1.0
String reasoning
) {}// ClassifySkill.java
package me.johnra.tutorial.skills;
import com.fasterxml.jackson.databind.ObjectMapper;
import dev.langchain4j.model.chat.ChatLanguageModel;
import java.util.List;
import java.util.stream.Collectors;
public class ClassifySkill extends BaseSkill<ClassificationResult> {
private static final ObjectMapper MAPPER = new ObjectMapper();
private final List<String> categories;
public ClassifySkill(ChatLanguageModel chatModel, List<String> categories) {
super(chatModel);
this.categories = categories;
}
@Override
public String skillName() { return "classify"; }
@Override
protected String buildSystemPrompt() {
String categoryList = categories.stream()
.map(c -> "- " + c)
.collect(Collectors.joining("\n"));
return """
You are a text classifier. Classify the input into exactly one of these categories:
%s
Respond in JSON only:
{"category": "<one of the categories above>", "confidence": <0.0 to 1.0>, "reasoning": "<one sentence>"}
No explanation. No markdown. Raw JSON only.
""".formatted(categoryList);
}
@Override
protected ClassificationResult parseResponse(String text) throws Exception {
ClassificationResult result = MAPPER.readValue(JsonExtractor.extract(text), ClassificationResult.class);
if (!categories.contains(result.category())) {
throw new IllegalArgumentException("Model returned unknown category: " + result.category());
}
return result;
}
}Step 3: The PolicyCheckSkill
The policy rules are injected at construction time, not hardcoded. This means the same skill class works for content moderation, code review policies, support ticket guidelines – whatever context you’re in.
// PolicyCheckResult.java
package me.johnra.tutorial.skills;
import java.util.List;
public record PolicyCheckResult(
boolean passed,
List<String> violations,
String severity // "none" | "minor" | "major" | "critical"
) {}// PolicyCheckSkill.java
package me.johnra.tutorial.skills;
import com.fasterxml.jackson.databind.ObjectMapper;
import dev.langchain4j.model.chat.ChatLanguageModel;
import java.util.List;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
public class PolicyCheckSkill extends BaseSkill<PolicyCheckResult> {
private static final ObjectMapper MAPPER = new ObjectMapper();
private final List<String> rules;
public PolicyCheckSkill(ChatLanguageModel chatModel, List<String> rules) {
super(chatModel);
this.rules = rules;
}
@Override
public String skillName() { return "policy_check"; }
@Override
protected String buildSystemPrompt() {
String rulesText = IntStream.range(0, rules.size())
.mapToObj(i -> (i + 1) + ". " + rules.get(i))
.collect(Collectors.joining("\n"));
return """
You are a content policy reviewer. Check the input against these rules:
%s
Respond in JSON only using this exact format:
{"passed": true|false, "violations": ["<rule>: <reason>", ...], "severity": "none|minor|major|critical"}
violations must be an array of plain strings, never objects.
Examples:
- Clean content: {"passed": true, "violations": [], "severity": "none"}
- One violation: {"passed": false, "violations": ["No competitor disparagement: content mocks a competitor by name"], "severity": "major"}
Severity guide:
- none: no violations
- minor: style issues, easily fixed
- major: significant problems requiring rework
- critical: harmful, illegal, or severely misleading content
No explanation outside the JSON. No markdown. Raw JSON only.
""".formatted(rulesText);
}
@Override
protected PolicyCheckResult parseResponse(String text) throws Exception {
return MAPPER.readValue(JsonExtractor.extract(text), PolicyCheckResult.class);
}
}Step 4: The SummarizeSkill
// SummarizeSkill.java
package me.johnra.tutorial.skills;
import dev.langchain4j.model.chat.ChatLanguageModel;
public class SummarizeSkill extends BaseSkill<String> {
private final int targetWords;
private final String style;
public SummarizeSkill(ChatLanguageModel chatModel, int targetWords, String style) {
super(chatModel);
this.targetWords = targetWords;
this.style = style;
}
public SummarizeSkill(ChatLanguageModel chatModel) {
this(chatModel, 150, "neutral");
}
@Override
public String skillName() { return "summarize"; }
@Override
protected String buildSystemPrompt() {
return """
You are an expert summarizer. Summarize the input in approximately %d words.
Style: %s
Return only the summary — no preamble, no meta-commentary, no "Here is a summary of..."
""".formatted(targetWords, style);
}
@Override
protected String parseResponse(String text) {
return text.strip();
}
}Step 5: The ExtractStructuredDataSkill
This one is the Swiss Army knife of the library. You define a Jackson-mapped Java class for what you want to extract; the skill figures out how to get it from unstructured text. Jackson’s ObjectMapper handles both schema generation and response deserialization.
// ExtractStructuredDataSkill.java
package me.johnra.tutorial.skills;
import com.fasterxml.jackson.databind.ObjectMapper;
import dev.langchain4j.model.chat.ChatLanguageModel;
import java.util.Arrays;
import java.util.stream.Collectors;
public class ExtractStructuredDataSkill<T> extends BaseSkill<T> {
private static final ObjectMapper MAPPER = new ObjectMapper();
private final Class<T> schema;
public ExtractStructuredDataSkill(ChatLanguageModel chatModel, Class<T> schema) {
super(chatModel);
this.schema = schema;
}
@Override
public String skillName() { return "extract_" + schema.getSimpleName().toLowerCase(); }
@Override
protected String buildSystemPrompt() {
String fields = describeFields();
return """
You are a data extraction assistant. Extract information from the input and return it as JSON.
Required JSON format:
{
%s
}
Return only valid JSON matching this format. No explanation, no preamble, no markdown fences.
""".formatted(fields);
}
@Override
protected T parseResponse(String text) throws Exception {
return MAPPER.readValue(JsonExtractor.extract(text), schema);
}
private String describeFields() {
if (schema.isRecord()) {
return Arrays.stream(schema.getRecordComponents())
.map(c -> " \"%s\": <%s>".formatted(c.getName(), c.getType().getSimpleName()))
.collect(Collectors.joining(",\n"));
}
return Arrays.stream(schema.getDeclaredFields())
.filter(f -> !f.isSynthetic())
.map(f -> " \"%s\": <%s>".formatted(f.getName(), f.getType().getSimpleName()))
.collect(Collectors.joining(",\n"));
}
}I’ve used this to extract meeting action items from transcripts, pull structured metadata from bug reports, and parse product specs from marketing briefs. It’s one of those capabilities that immediately makes you wonder what you were doing without it.
Step 6: Wiring Skills into the Agent and Workflow
Here’s the payoff. Watch how the systems from Parts 1 and 2 get simpler when they’re calling skills instead of doing their own AI work.
In the bug investigation agent (from Part 1):
// SkillConfig.java — instantiate skills as Spring beans so they can be reused anywhere
package me.johnra.tutorial.skills.config;
import dev.langchain4j.model.chat.ChatLanguageModel;
import me.johnra.tutorial.skills.ClassifySkill;
import me.johnra.tutorial.skills.ContentReadinessSkill;
import me.johnra.tutorial.skills.PolicyCheckSkill;
import me.johnra.tutorial.skills.SummarizeSkill;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import java.util.List;
@Configuration
public class SkillConfig {
private static final List<String> CONTENT_POLICY_RULES = List.of(
"No unverified statistics presented as fact",
"No competitor disparagement",
"Medical/legal/financial claims require disclaimers",
"No misleading headlines"
);
@Bean
public ClassifySkill bugClassifySkill(ChatLanguageModel chatModel) {
return new ClassifySkill(chatModel,
List.of("null_reference", "off_by_one", "race_condition",
"data_corruption", "configuration", "other"));
}
@Bean
public PolicyCheckSkill contentPolicySkill(ChatLanguageModel chatModel) {
return new PolicyCheckSkill(chatModel, CONTENT_POLICY_RULES);
}
@Bean
public SummarizeSkill editorialSummarizer(ChatLanguageModel chatModel) {
return new SummarizeSkill(chatModel, 100, "editorial");
}
@Bean
public ContentReadinessSkill contentReadinessSkill(
ClassifySkill bugClassifySkill,
PolicyCheckSkill contentPolicySkill,
SummarizeSkill editorialSummarizer) {
return new ContentReadinessSkill(bugClassifySkill, contentPolicySkill, editorialSummarizer);
}
}Alternatively, you can expose the skills via REST API and register them through MCP
// In BugInvestigationTools.java — inject the ClassifySkill bean, call it in a tool method
@Tool("Classify a bug description into a known bug category.")
public String classifyBug(
@P("The bug description to classify") String description) {
enforceToolBudget();
SkillResult<ClassificationResult> result = bugClassifySkill.run(description);
return "Bug category: %s (confidence: %.0f%%)%nReasoning: %s".formatted(
result.output().category(),
result.output().confidence() * 100,
result.output().reasoning());
}In the content pipeline (from Part 2) – the compliance and summary steps become one-liners:
// ContentPipelineService.java — with skill beans injected
@Service
public class ContentPipelineService {
private final PolicyCheckSkill policySkill;
private final ClassifySkill audienceSkill;
private final SummarizeSkill summarizer;
// ... other deps
public ContentAnalysis process(String draft) throws Exception {
// Step 1: Classify — one line
SkillResult<ClassificationResult> classification = audienceSkill.run(draft);
// Steps 2A + 2B: parallel — skills compose cleanly with CompletableFuture
CompletableFuture<SkillResult<PolicyCheckResult>> complianceFuture =
CompletableFuture.supplyAsync(() -> policySkill.run(draft));
CompletableFuture<SkillResult<String>> summaryFuture =
CompletableFuture.supplyAsync(() -> summarizer.run(draft));
CompletableFuture.allOf(complianceFuture, summaryFuture).join();
RouteDecision route = routingService.determineRoute(
complianceFuture.get().output(),
classification.output());
return new ContentAnalysis(
classification.output().category(),
// ... remaining fields
route,
null
);
}
}The orchestration code is now almost trivially simple. All the interesting work is in the skills, where it belongs.
Testing Your Skills: This Is Where You Win
This is the architectural dividend. Each skill is independently testable. You don’t need to spin up an agent or a full pipeline to verify that your policy checker works correctly. You just call it with known inputs and assert on the outputs.
// PolicyCheckSkillTest.java
package me.johnra.tutorial.skills;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.ollama.OllamaChatModel;
import org.junit.jupiter.api.BeforeEach;
import org.junit.jupiter.api.Test;
import java.time.Duration;
import java.util.List;
import static org.assertj.core.api.Assertions.assertThat;
class PolicyCheckSkillTest {
private PolicyCheckSkill skill;
@BeforeEach
void setUp() {
ChatLanguageModel model = OllamaChatModel.builder()
.baseUrl("http://localhost:11434")
.modelName("llama3.2")
.temperature(0.0)
.timeout(Duration.ofSeconds(60))
.build();
skill = new PolicyCheckSkill(model, List.of(
"No unverified statistics",
"No competitor disparagement"
));
}
@Test
void cleanContentPasses() {
SkillResult<PolicyCheckResult> result = skill.run(
"Java is a great programming language for enterprise applications."
);
assertThat(result.output().passed()).isTrue();
assertThat(result.output().severity()).isEqualTo("none");
}
@Test
void violationIsDetected() {
SkillResult<PolicyCheckResult> result = skill.run(
"Studies show 99% of users prefer our product over CompetitorX, which is terrible."
);
assertThat(result.output().passed()).isFalse();
assertThat(result.output().violations()).isNotEmpty();
}
@Test
void resultCarriesObservabilityMetadata() {
SkillResult<PolicyCheckResult> result = skill.run("Some perfectly reasonable content.");
assertThat(result.latencyMs()).isPositive();
assertThat(result.skillName()).isEqualTo("policy_check");
}
}Yes, these tests make real model calls. They cost tokens. Run them in CI on a nightly schedule, not on every commit. The important thing is that they exist and they’re testing the actual behavior of the skill with a real model – not a mock that might silently drift from reality.
Composing Skills into Higher-Order Skills
Once you have atomic skills, you can compose them into compound skills without any magic – just regular method calls.
// ContentReadinessResult.java
package me.johnra.tutorial.skills;
import java.util.List;
public record ContentReadinessResult(
boolean readyForPublication,
String summary,
String audience,
List<String> blockers
) {}// ContentReadinessSkill.java — a compound skill that composes three atomic skills
package me.johnra.tutorial.skills;
import java.util.ArrayList;
import java.util.List;
public class ContentReadinessSkill implements Skill<ContentReadinessResult> {
private final Skill<ClassificationResult> classifier;
private final Skill<PolicyCheckResult> policyChecker;
private final Skill<String> summarizer;
public ContentReadinessSkill(
Skill<ClassificationResult> classifier,
Skill<PolicyCheckResult> policyChecker,
Skill<String> summarizer) {
this.classifier = classifier;
this.policyChecker = policyChecker;
this.summarizer = summarizer;
}
@Override
public String skillName() { return "content_readiness"; }
@Override
public SkillResult<ContentReadinessResult> run(String content) {
long start = System.currentTimeMillis();
SkillResult<ClassificationResult> audience = classifier.run(content);
SkillResult<PolicyCheckResult> policy = policyChecker.run(content);
SkillResult<String> summary = summarizer.run(content);
List<String> blockers = new ArrayList<>(policy.output().violations());
if (List.of("major", "critical").contains(policy.output().severity())) {
blockers.add("Policy severity: " + policy.output().severity());
}
ContentReadinessResult result = new ContentReadinessResult(
policy.output().passed() && blockers.isEmpty(),
summary.output(),
audience.output().category(),
blockers);
return new SkillResult<>(result, "composite", 0, 0,
System.currentTimeMillis() - start, skillName());
}
}Two things are different from the naïve version. First, ContentReadinessSkill implements Skill<ContentReadinessResult> – it satisfies the same interface as atomic skills, so it can be registered, looked up by name, and injected anywhere a Skill<ContentReadinessResult> is expected. Second, the constructor takes Skill<X> interfaces, not concrete classes. The composition code doesn’t know or care whether the classifier is a ClassifySkill backed by Ollama, a stub in a test, or a future cached variant – any Skill<ClassificationResult> works.
This is how you build a platform rather than a feature. Atomic skills compose into compound skills. Compound skills slot into agents and workflows. The whole system is testable at every layer. When something breaks, you know exactly which layer to look at.
The Skill Registry: Your Internal AI Catalog
At scale – and this happens sooner than you’d expect – you want a registry. A central catalog of available skills that agents and workflows can discover without having to know the implementation details.
// SkillRegistry.java
package me.johnra.tutorial.skills;
import org.springframework.stereotype.Component;
import java.util.Collection;
import java.util.Map;
import java.util.Optional;
import java.util.concurrent.ConcurrentHashMap;
@Component
public class SkillRegistry {
private final Map<String, Skill<?>> skills = new ConcurrentHashMap<>();
public SkillRegistry register(Skill<?> skill) {
skills.put(skill.skillName(), skill);
return this;
}
public Optional<Skill<?>> get(String name) {
return Optional.ofNullable(skills.get(name));
}
public Collection<String> list() {
return skills.keySet();
}
}The registry stores Skill<?>, not BaseSkill<?>. Any class that implements Skill<T> can be registered – including composite skills like ContentReadinessSkill that don’t extend BaseSkill at all. Adding a new type of skill (say, one backed by a different model provider, or a deterministic rule-based skill with no model call) requires zero changes to the registry.
// SkillRegistryConfig.java — register all skills at application startup
package me.johnra.tutorial.skills.config;
import me.johnra.tutorial.skills.ClassifySkill;
import me.johnra.tutorial.skills.ContentReadinessSkill;
import me.johnra.tutorial.skills.PolicyCheckSkill;
import me.johnra.tutorial.skills.SkillRegistry;
import me.johnra.tutorial.skills.SummarizeSkill;
import org.springframework.boot.ApplicationRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.annotation.Order;
@Configuration
public class SkillRegistryConfig {
@Bean
@Order(1)
public ApplicationRunner registerSkills(
SkillRegistry registry,
ClassifySkill bugClassifySkill,
PolicyCheckSkill contentPolicySkill,
SummarizeSkill editorialSummarizer,
ContentReadinessSkill contentReadinessSkill) {
return args -> {
registry
.register(bugClassifySkill)
.register(contentPolicySkill)
.register(editorialSummarizer)
.register(contentReadinessSkill);
System.out.println("Skills registered: " + registry.list());
};
}
}When a new engineer joins and wants to add AI behavior to their feature, they check the registry first. Maybe the skill they need already exists. If it does, they use it. If it doesn’t, they add it to the registry and everyone benefits. This is the culture change that the skill library enables – AI capabilities become a shared resource, not a copy-paste artifact.
Source code is available at https://github.com/johnra74/tutorial-agents-workflow-tools/tree/main/part3-skills-library
The Complete Picture
Here’s the architecture that emerges when all three parts work together:
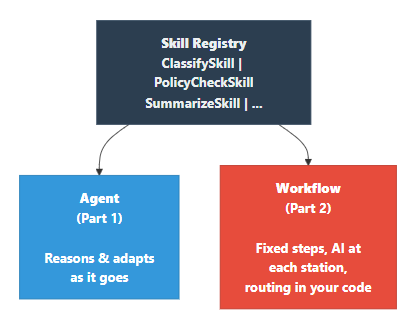
The decision matrix, as simply as I can put it:
| The problem looks like… | Reach for… |
|---|---|
| I don’t know what steps to take yet | Agent |
| I know the steps but need AI at each one | Workflow |
| I’ve written this capability twice already | Skill |
| I need reproducibility, auditability | Workflow |
| Open-ended, exploratory, adaptive | Agent |
| Something new that will clearly be reused | Skill first, wire it in second |
It’s Always Been About the Seams
The 3-layer model – skills, workflows, agents – is fundamentally about where you put the seams in your system. A seam is where one component ends and another begins. Good seams are testable on each side independently, typed so the contract is explicit, and stable enough that implementations can change without breaking callers.
The worst AI systems, like many failed traditional systems I’ve reviewed, are monolithic – one massive prompt, one enormous function that does classification and extraction and policy checking and routing all interleaved. They work, until they suddenly don’t, and nobody can tell you which part failed because there are no seams to test independently.

With AI in the mix, the bar has shifted: anyone can craft a prompt that yields working code. But working code isn’t the same as a well-designed system. That gap/seams still matters – and it’s where real engineering judgment shows up.
The best AI systems look a lot like the best non-AI systems: small, focused components with clear interfaces, composed into larger capabilities at a higher layer. The seams are explicit. The responsibilities are clear. You can hand a new engineer the PolicyCheckSkill and they can understand it, test it, and use it without reading the rest of the codebase.
Over 25 years of experience in software engineering has taught me a simple core lesson: the hard part is never the code that works once. It’s the code that keeps working, by a rotating team, under changing requirements, for years. Agents don’t change this. Workflows don’t change this. Skills don’t change this. The principles of good engineering practices are the same. You’re just applying them to a new kind of component.
Build the right thing. Build it with clean seams. And when you’re not sure which thing is right, start simpler than you think you need to – and add complexity only when you have evidence you need it.