A 3-Part Series: Agents, Workflows, and Skills – Build the Right Thing
There’s a phrase I’ve used in engineering reviews for years, usually right before someone’s six-week project gets redirected: “Don’t hire a strategist when you need a soldier.”
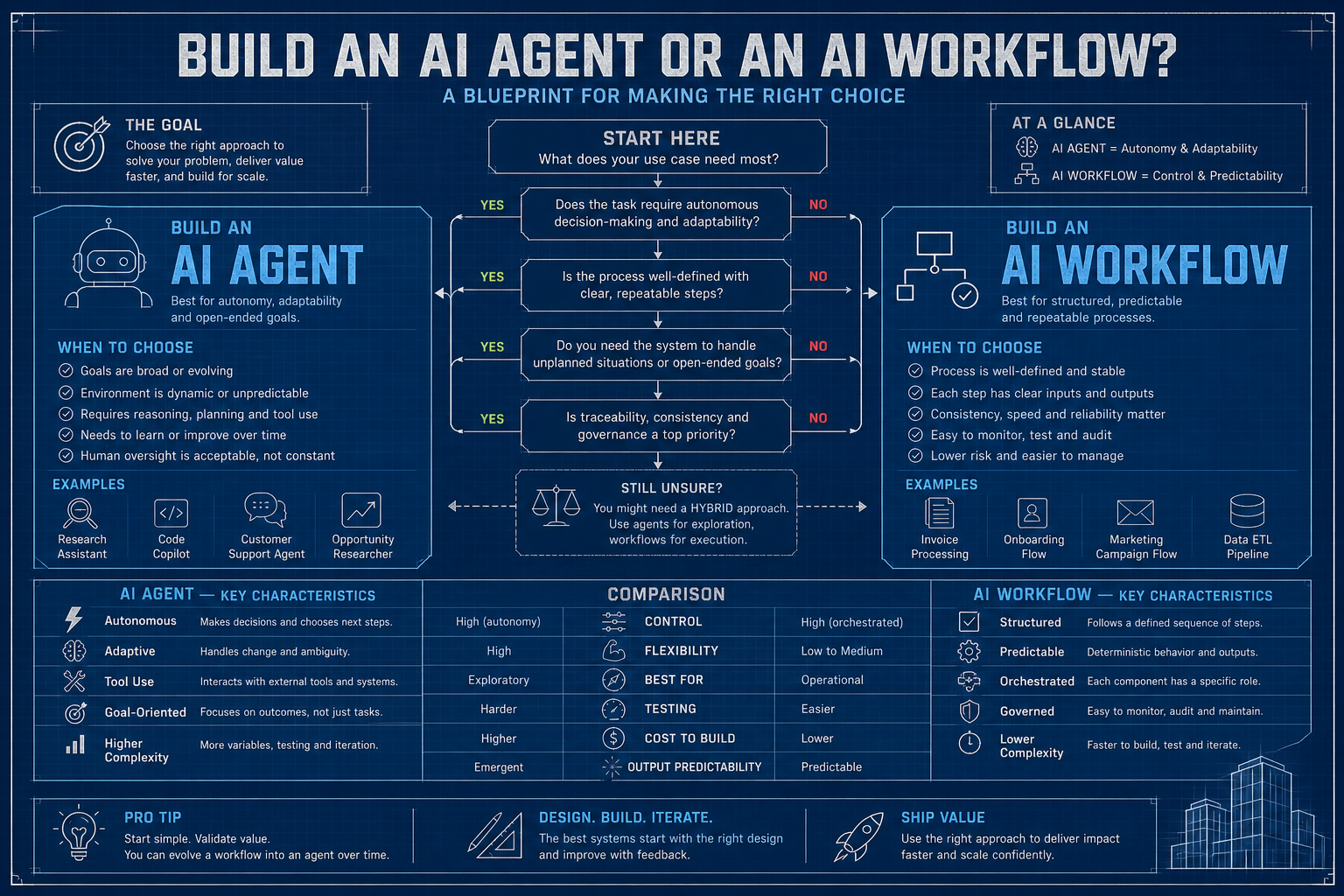
In Part 1, we discuss agents – an autonomous AI system that reasons its way through open-ended problem. If you read it, you know I’m a fan. They’re genuinely capable, and when you deploy one in the right context, it feels like a superpower. But here’s the thing nobody says out loud at AI conferences: most of what you actually need to build doesn’t require a strategist at all.

Most real-world AI tasks are predictable, structured, and repetitive – deterministic. The same types of content get processed every day. The same kinds of requests come in. The same steps need to happen, in the same order, with the same checks. Dropping an autonomous agent into that situation is like hiring a grandmaster chess player to sort your mail. Technically capable. Wildly overkill. And now you’re paying grandmaster rates for envelope sorting.
That’s exactly what workflows are for. Both approaches may work, but one usually comes with unnecessary token consumption, added operational overhead, and higher long-term cost. Agents are the new shiny thing, and they absolutely have their place. But for roughly 80% of what’s being labeled “AI automation” today, a well-designed workflow is still the better default.
What Is a Workflow?
A workflow is a predefined sequence of steps – some deterministic, some AI-powered – where the structure of execution is known before the work begins. The crucial insight: the AI doesn’t decide what happens next. You do. The AI handles the within-step intelligence – generating text, classifying input, extracting information, scoring quality – but the routing, sequencing, and decision logic live in your code, where they can be tested, audited, and explained to a regulator if necessary.
Why Workflow Gets Systematically Underestimated
Let’s face it, the industry is infatuated with agents right now, and I understand why. Watching an AI autonomously investigate a bug, write a patch, and open a PR is genuinely impressive. It makes a great conference demo. It gets you invited to speak on panels. But I’ve seen what happens when those demos hit production, and it is not always a panel-worthy story.
Here’s why workflows quietly outperform agents for the majority of real tasks:
- Reliability: Workflows behave the same way each run. You can write integration tests. You know exactly where in the process a failure happened, because the process is explicit in your code.
- Cost: Each agent iteration is a model call. Agents can surprise you at the end of the month in ways that require uncomfortable conversations with finance. Workflows use exactly as many model calls as you designed. Not one more.
- Latency: You can parallelize workflow steps. Independent sub-tasks run concurrently. Meanwhile, an agent thinks sequentially – each step informs the next in a non-deterministic way. This matters when you’re processing thousands of items a day where every step may vary.
- Auditability: Every step in a workflow is a named function with inputs and outputs. Your legal and compliance teams will, for once in your career, be happy with you. Cherish this.
- Debuggability: When something goes wrong in a workflow, you open the log for that step and find the problem. When something goes wrong in an agent, you read a transcript and try to figure out why the model decided to search for the same term seventeen times.
The mental shift that changes everything: don’t start with an agent and constrain it. Start with a workflow and add AI where you need intelligence.
When to Build a Workflow
4 questions. Again, honest answers only.
1. Can I whiteboard the process from start to finish?
If you can draw the steps – even with branches and conditions – you can build a workflow. If you find yourself saying “well, it depends on what the AI finds at step 3,” that’s an agent. The tell is whether you’d feel comfortable writing unit tests for the routing logic. If yes: workflow.
2. Do you need reproducibility or auditability?
Compliance, legal, financial, healthcare – anywhere humans need to verify what happened and why – workflows win by a mile. This isn’t a preference thing; it’s a “your governance team will thank you” thing. You don’t want to be in the room where audit teams asked why a particular decision was made in an automated system. “The AI decided” is never an acceptable answer.
3. Are there parallel tracks?
Workflows can fan out. Run a policy check and a quality score simultaneously. Cut processing time in half. An agent loop is inherently sequential – remember, an output of one action informs the next action. If your process has genuinely independent sub-tasks, you’re leaving performance on the table with an agent.
4. Are cost or latency real constraints?
With workflows, you design the model call budget upfront. You know what it costs before you ship it. That’s a rare and valuable thing.
Build a workflow when: the process is known, reliability matters, you need auditability, or you have parallelizable steps.
Don’t build a workflow when: the problem is genuinely open-ended, the path depends on what you discover, or you need AI to reason about what to do rather than how well to do a defined thing.
The Hybrid That Actually Ships
In practice, the systems that hold up in production usually combine both. Here’s a pattern I’ve seen succeed repeatedly across teams:
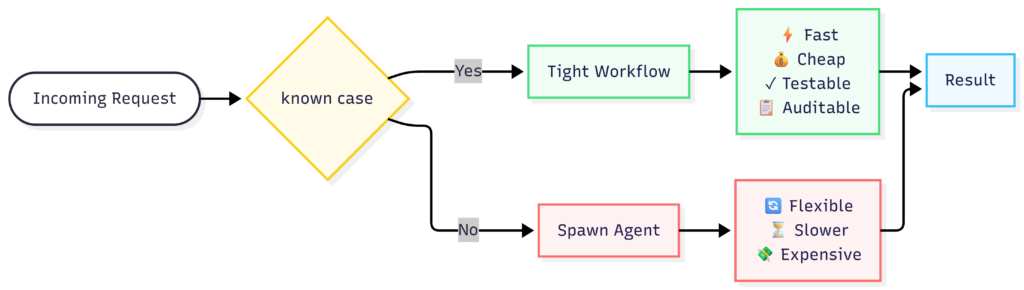
The workflow handles the predictable core. The agent handles the long tail. You get reliability by default and flexibility where you actually need it. This is not a compromise – it’s the right architecture. The mistake most teams make is designing for the long tail first. It’s more interesting to build, and it makes a better demo. But your users live in the 85%.
Step-by-Step: Building an AI-Powered Content Pipeline
We’ll use a content publishing pipeline as the example – its a domain I’ve spent over 4 years of my career on, from processing content drafts, customer support tickets, or product descriptions.
We’ll use Java, Spring Boot, LangChain4j, and Ollama running locally.
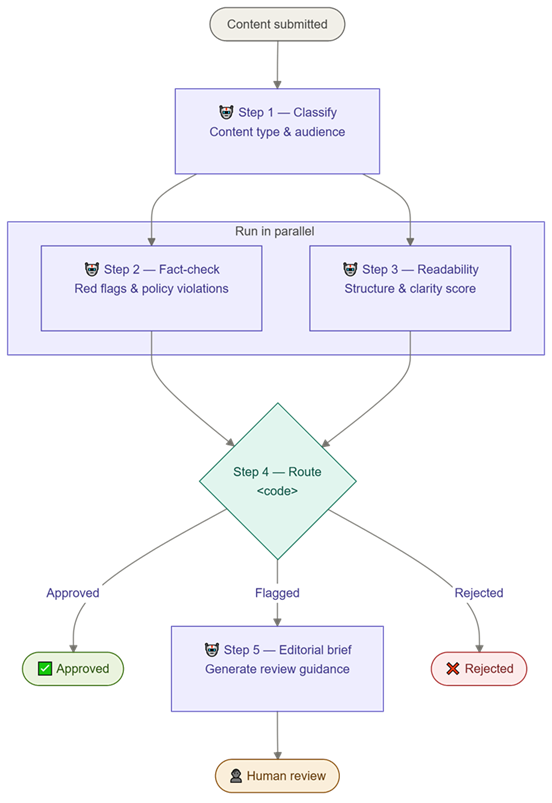
Use case: Automated Content Quality Pipeline
Given a draft content post, the pipeline will:
- Classify the content type and audience (AI step)
- Check for factual red flags and policy violations (AI step, runs in parallel with step 3)
- Score readability and structure (AI step, runs in parallel with step 2)
- Route based on results – approve, flag for human review, or reject (code, not AI)
- Generate an editorial brief if flagged (AI step, only if needed)
Prerequisites
Ollama running locally with a model that supports instruction-following:
ollama pull llama3.1Step 1: Define the Pipeline Structure
<!-- pom.xml -->
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.3.4</version>
</parent>
<groupId>me.johnra.tutorial</groupId>
<artifactId>part2-content-pipeline</artifactId>
<name>Part 2 — Content Quality Pipeline</name>
<version>1.0.0</version>
<properties>
<java.version>21</java.version>
<langchain4j.version>0.36.2</langchain4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-ollama</artifactId>
<version>${langchain4j.version}</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>Java records are the typed contract for every pipeline result – immutable, concise, and understood by Jackson for JSON deserialization.
// RouteDecision.java
package me.johnra.tutorial.pipeline.model;
public enum RouteDecision {
APPROVE, FLAG_FOR_REVIEW, REJECT
}// ContentAnalysis.java — the final result of the pipeline run
package me.johnra.tutorial.pipeline.model;
import java.util.List;
public record ContentAnalysis(
String contentType,
String targetAudience,
List<String> policyViolations,
int readabilityScore,
int structureScore,
RouteDecision route,
String editorialBrief // null when route == APPROVE or REJECT
) {}Step 2: Build Each Step as a Focused Function
Each step is a single, well-scoped AI call. Not a loop. Not an agent. One call, one result, one responsibility. I can’t stress this enough – the discipline of keeping steps focused is what makes the whole thing testable. In LangChain4j, you declare what each step does as a Java interface. The framework handles prompt assembly and response parsing. LangChain4j can also deserialize model output directly into Java records when Jackson is on the classpath.
First, the result records and AI service interfaces:
// ClassificationResult.java
package me.johnra.tutorial.pipeline.model;
public record ClassificationResult(
String contentType, // tutorial|opinion|news|product|other
String targetAudience, // beginner|intermediate|advanced|general
int estimatedReadTimeMinutes
) {}// ContentClassifier.java — Step 1: classify content type and audience
package me.johnra.tutorial.pipeline.service;
import me.johnra.tutorial.pipeline.model.ClassificationResult;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
public interface ContentClassifier {
@SystemMessage("""
You are a content classifier. Classify the provided content.
Respond with a JSON object matching this schema exactly:
{
"contentType": "tutorial|opinion|news|product|other",
"targetAudience": "beginner|intermediate|advanced|general",
"estimatedReadTimeMinutes": <integer>
}
Return only the JSON object, no explanation.
""")
ClassificationResult classify(@UserMessage String content);
}// ComplianceResult.java
package me.johnra.tutorial.pipeline.model;
import java.util.List;
public record ComplianceResult(
List<String> violations,
String severity // none|minor|major|critical
) {}// PolicyComplianceChecker.java — Step 2A: runs in parallel with readability scoring
package me.johnra.tutorial.pipeline.service;
import me.johnra.tutorial.pipeline.model.ComplianceResult;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
public interface PolicyComplianceChecker {
@SystemMessage("""
You are a content policy reviewer. Check for:
- Medical/legal/financial claims without caveats
- Harmful or discriminatory language
- Unverifiable statistics presented as fact
- Competitor disparagement
Respond with a JSON object matching this schema exactly:
{
"violations": ["description of each violation, or empty array if none"],
"severity": "none|minor|major|critical"
}
Return only the JSON object, no explanation.
""")
ComplianceResult check(@UserMessage String content);
}// ReadabilityResult.java
package me.johnra.tutorial.pipeline.model;
public record ReadabilityResult(
int readabilityScore, // 1-10
int structureScore, // 1-10
int engagementScore, // 1-10
String topImprovement
) {}// ReadabilityScorer.java — Step 2B: runs in parallel with compliance check
package me.johnra.tutorial.pipeline.service;
import me.johnra.tutorial.pipeline.model.ReadabilityResult;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
public interface ReadabilityScorer {
@SystemMessage("""
You are an editorial quality reviewer. Score the content on:
- Readability (clarity, sentence length, vocabulary): 1-10
- Structure (clear intro/body/conclusion, logical flow, headers): 1-10
- Engagement (compelling opening, examples, calls to action): 1-10
Respond with a JSON object matching this schema exactly:
{
"readabilityScore": <1-10>,
"structureScore": <1-10>,
"engagementScore": <1-10>,
"topImprovement": "single most impactful improvement suggestion"
}
Return only the JSON object, no explanation.
""")
ReadabilityResult score(@UserMessage String content);
}// EditorialBriefWriter.java — Step 4 (conditional)
package me.johnra.tutorial.pipeline.service;
import dev.langchain4j.service.SystemMessage;
import dev.langchain4j.service.UserMessage;
public interface EditorialBriefWriter {
@SystemMessage("""
You are a senior editor. Write a concise editorial brief for the human reviewer.
Be specific, actionable, and professional. 3-5 bullet points maximum.
Return only the brief, no preamble.
""")
String writeBrief(@UserMessage String analysisAndContent);
}Step 3: Build the Routing Logic in Code – Not AI
This is the part most teams get wrong the first time, and it’s the most important step in the whole pipeline. The routing logic lives in Java. Not in a prompt. Not in the model’s judgment. In a Java class that you can test with JUnit in milliseconds.
// ContentRouter.java — pure logic, no AI, fully testable
package me.johnra.tutorial.pipeline.service;
import me.johnra.tutorial.pipeline.model.ComplianceResult;
import me.johnra.tutorial.pipeline.model.ReadabilityResult;
import me.johnra.tutorial.pipeline.model.RouteDecision;
import org.springframework.stereotype.Component;
@Component
public class ContentRouter {
public RouteDecision determine(ComplianceResult compliance, ReadabilityResult quality) {
// Critical violations always reject — no exceptions, no ambiguity
if ("critical".equals(compliance.severity())) {
return RouteDecision.REJECT;
}
// Major violations: flag for a human to sort out
if ("major".equals(compliance.severity())) {
return RouteDecision.FLAG_FOR_REVIEW;
}
double avgQuality = (quality.readabilityScore() +
quality.structureScore() +
quality.engagementScore()) / 3.0;
// Below 5 average: too rough, needs work
if (avgQuality < 5.0) {
return RouteDecision.FLAG_FOR_REVIEW;
}
// Minor violations or borderline quality: human eyes can make the call
if (!compliance.violations().isEmpty() || avgQuality < 7.0) {
return RouteDecision.FLAG_FOR_REVIEW;
}
return RouteDecision.APPROVE;
}
}Note: this class has no model calls. No AI. It’s plain Java. You can write JUnit tests for it that run in milliseconds. The AI evaluated the content; you decide what to do with the evaluation.
Step 4: Orchestrate the Pipeline
Now we wire everything together. Steps 2A and 2B run concurrently using CompletableFuture and Java 21 virtual threads – this is the moment where the workflow architecture pays off in actual wall-clock time.
// PipelineConfig.java — Spring config wiring all AI services and enabling async
package me.johnra.tutorial.pipeline.config;
import me.johnra.tutorial.pipeline.service.*;
import dev.langchain4j.model.chat.ChatLanguageModel;
import dev.langchain4j.model.ollama.OllamaChatModel;
import dev.langchain4j.service.AiServices;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.scheduling.annotation.EnableAsync;
import java.time.Duration;
import java.util.concurrent.Executor;
import java.util.concurrent.Executors;
@Configuration
@EnableAsync
public class PipelineConfig {
@Value("${ollama.base-url:http://localhost:11434}")
private String baseUrl;
@Value("${ollama.model:llama3.2}")
private String modelName;
@Bean
public ChatLanguageModel chatModel() {
return OllamaChatModel.builder()
.baseUrl(baseUrl)
.modelName(modelName)
.temperature(0.0)
.timeout(Duration.ofSeconds(120))
.build();
}
@Bean public ContentClassifier contentClassifier(ChatLanguageModel m) {
return AiServices.create(ContentClassifier.class, m);
}
@Bean public PolicyComplianceChecker policyComplianceChecker(ChatLanguageModel m) {
return AiServices.create(PolicyComplianceChecker.class, m);
}
@Bean public ReadabilityScorer readabilityScorer(ChatLanguageModel m) {
return AiServices.create(ReadabilityScorer.class, m);
}
@Bean public EditorialBriefWriter editorialBriefWriter(ChatLanguageModel m) {
return AiServices.create(EditorialBriefWriter.class, m);
}
@Bean(name = "pipelineExecutor")
public Executor pipelineExecutor() {
return Executors.newVirtualThreadPerTaskExecutor(); // Java 21 virtual threads
}
}// ContentPipelineService.java — orchestrates the full workflow
package me.johnra.tutorial.pipeline.service;
import me.johnra.tutorial.pipeline.model.*;
import org.springframework.stereotype.Service;
import java.util.concurrent.CompletableFuture;
@Service
public class ContentPipelineService {
private final ContentClassifier classifier;
private final PolicyComplianceChecker complianceChecker;
private final ReadabilityScorer readabilityScorer;
private final EditorialBriefWriter briefWriter;
private final ContentRouter router;
public ContentPipelineService(ContentClassifier classifier,
PolicyComplianceChecker complianceChecker,
ReadabilityScorer readabilityScorer,
EditorialBriefWriter briefWriter,
ContentRouter router) {
this.classifier = classifier;
this.complianceChecker = complianceChecker;
this.readabilityScorer = readabilityScorer;
this.briefWriter = briefWriter;
this.router = router;
}
public ContentAnalysis analyze(String draft) {
// Step 1: Classify
System.out.println("Step 1: Classifying content...");
ClassificationResult classification = classifier.classify(draft);
System.out.printf(" → %s for %s audience%n",
classification.contentType(), classification.targetAudience());
// Steps 2A + 2B: Run in parallel — half the wall-clock time vs. sequential
System.out.println("Steps 2A + 2B: Compliance check and quality scoring running in parallel...");
CompletableFuture<ComplianceResult> complianceFuture =
CompletableFuture.supplyAsync(() -> complianceChecker.check(draft));
CompletableFuture<ReadabilityResult> qualityFuture =
CompletableFuture.supplyAsync(() -> readabilityScorer.score(draft));
ComplianceResult compliance = complianceFuture.join();
ReadabilityResult quality = qualityFuture.join();
System.out.printf(" → Compliance severity: %s%n", compliance.severity());
System.out.printf(" → Quality scores: readability=%d, structure=%d%n",
quality.readabilityScore(), quality.structureScore());
// Step 3: Route — pure logic, no AI, fully testable
RouteDecision route = router.determine(compliance, quality);
System.out.printf("Step 3: Routing decision → %s%n", route);
// Step 4: Conditional — only runs if something needs human review
String editorialBrief = null;
if (route == RouteDecision.FLAG_FOR_REVIEW) {
System.out.println("Step 4: Generating editorial brief for reviewer...");
String context = """
Content type: %s | Audience: %s
Violations: %s | Severity: %s
Readability: %d/10 | Structure: %d/10
Top improvement: %s
Content:
%s
""".formatted(
classification.contentType(), classification.targetAudience(),
compliance.violations(), compliance.severity(),
quality.readabilityScore(), quality.structureScore(),
quality.topImprovement(),
draft.substring(0, Math.min(draft.length(), 1500)));
editorialBrief = briefWriter.writeBrief(context);
}
return new ContentAnalysis(
classification.contentType(),
classification.targetAudience(),
compliance.violations(),
quality.readabilityScore(),
quality.structureScore(),
route,
editorialBrief
);
}
}Step 5: Run It
Let’s give it something spicy to process. I based this draft on content I’ve seen on LinkedIn – the AI industry attracts a lot of Very Confident Writers.
// ContentPipelineApplication.java
package me.johnra.tutorial.pipeline;
import me.johnra.tutorial.pipeline.model.ContentAnalysis;
import me.johnra.tutorial.pipeline.service.ContentPipelineService;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class ContentPipelineApplication implements CommandLineRunner {
private final ContentPipelineService pipelineService;
public ContentPipelineApplication(ContentPipelineService pipelineService) {
this.pipelineService = pipelineService;
}
public static void main(String[] args) {
SpringApplication.run(ContentPipelineApplication.class, args);
}
@Override
public void run(String... args) {
String draft = """
# 5 Ways AI Will Replace Every Developer by 2025
Studies show that 90% of coding jobs will be automated within 18 months.
As someone who has personally spoken with 50 Fortune 500 CEOs, I can confirm
that mass layoffs are coming. Our product, DevKiller Pro, is the only tool
that will help you survive this transition. Unlike our competitors who are
hiding this information, we're being honest with you...
""";
ContentAnalysis result = pipelineService.analyze(draft);
System.out.println("\n" + "=".repeat(50));
System.out.printf("PIPELINE RESULT: %s%n", result.route());
System.out.println("=".repeat(50));
System.out.printf("Content type: %s%n", result.contentType());
System.out.printf("Violations: %s%n", result.policyViolations());
System.out.printf("Readability: %d/10%n", result.readabilityScore());
System.out.printf("Structure: %d/10%n", result.structureScore());
if (result.editorialBrief() != null) {
System.out.println("\nEditorial Brief:\n" + result.editorialBrief());
}
}
}Spoiler! It gets flagged. Possibly rejected. The editorial brief will not be kind. This is working as designed.
Agent in Action
Source code is available at https://github.com/johnra74/tutorial-agents-workflow-tools/tree/main/part2-content-pipeline
$ mvn spring-boot:run
[INFO] Scanning for projects...
[INFO]
[INFO] -------------< me.johnra.tutorial:part2-content-pipeline >--------------
[INFO] Building Part 2 — Content Quality Pipeline 1.0.0
[INFO] --------------------------------[ jar ]---------------------------------
[INFO]
[INFO] >>> spring-boot-maven-plugin:3.3.4:run (default-cli) > test-compile @ part2-content-pipeline >>>
[INFO]
[INFO] --- maven-resources-plugin:3.3.1:resources (default-resources) @ part2-content-pipeline ---
[INFO] Copying 1 resource from src/main/resources to target/classes
[INFO] Copying 0 resource from src/main/resources to target/classes
[INFO]
[INFO] --- maven-compiler-plugin:3.13.0:compile (default-compile) @ part2-content-pipeline ---
[INFO] Nothing to compile - all classes are up to date.
[INFO]
[INFO] --- maven-resources-plugin:3.3.1:testResources (default-testResources) @ part2-content-pipeline ---
[INFO] skip non existing resourceDirectory /***/part2-content-pipeline/src/test/resources
[INFO]
[INFO] --- maven-compiler-plugin:3.13.0:testCompile (default-testCompile) @ part2-content-pipeline ---
[INFO] Nothing to compile - all classes are up to date.
[INFO]
[INFO] <<< spring-boot-maven-plugin:3.3.4:run (default-cli) < test-compile @ part2-content-pipeline <<<
[INFO]
[INFO]
[INFO] --- spring-boot-maven-plugin:3.3.4:run (default-cli) @ part2-content-pipeline ---
[INFO] Attaching agents: []
. ____ _ __ _ _
/\\ / ___'_ __ _ _(_)_ __ __ _ \ \ \ \
( ( )\___ | '_ | '_| | '_ \/ _` | \ \ \ \
\\/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |_\__, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v3.3.4)
2026-05-06T21:22:35.577Z INFO 5263 --- [ main] m.j.t.p.ContentPipelineApplication : Starting ContentPipelineApplication using Java 21.0.10 with PID 5263 (/***/part2-content-pipeline/target/classes started by *** in /***/part2-content-pipeline)2026-05-06T21:22:35.578Z INFO 5263 --- [ main] m.j.t.p.ContentPipelineApplication : No active profile set, falling back to 1 default profile: "default"
2026-05-06T21:22:36.220Z INFO 5263 --- [ main] m.j.t.p.ContentPipelineApplication : Started ContentPipelineApplication in 0.857 seconds (process running for 1.044)
Step 1: Classifying content...
→ opinion for advanced audience (~5 min read)
Steps 2A + 2B: Compliance check and quality scoring running in parallel...
→ Compliance severity: major | violations: 2
→ Quality: readability=4, structure=6, engagement=8
Step 3: Routing decision → FLAG_FOR_REVIEW
Step 4: Generating editorial brief for reviewer...
============================================================
PIPELINE RESULT: FLAG_FOR_REVIEW
============================================================
Content type: opinion
Audience: advanced
Violations: [Unverifiable statistics presented as fact: '90% of coding jobs will be automated within 18 months', Competitor disparagement: 'our competitors who are hiding this information']
Readability: 4/10
Structure: 6/10
Editorial Brief:
**Editorial Brief**
* Revise the opening sentence to provide a more nuanced and evidence-based claim about automation in coding jobs, avoiding unverifiable statistics.
* Break up long sentences and rephrase them for improved clarity, aiming for a readability score of 7-8/10.
* Remove competitor disparagement language and focus on highlighting the unique value proposition of DevKiller Pro without making unsubstantiated claims.
[INFO] ------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO] ------------------------------------------------------------------------
[INFO] Total time: 18.253 s
[INFO] Finished at: 2026-05-06T21:22:52Z
[INFO] ------------------------------------------------------------------------Patterns That Separate Production from Prototype
Here are some common pitfalls to be aware of before moving to production
1. Typed Inputs and Outputs for Every Step
Java records are the typed contract. This discipline pays off every time. Change a field in a record, and the compiler tells you everywhere that breaks – not a runtime exception in production at midnight.
// Java records are the typed contract — immutable, concise, compiler-enforced.
// Change ComplianceResult and the compiler breaks every incompatible call site.
public record ComplianceResult(
List<String> violations,
String severity // none|minor|major|critical
) {}
// The AI service method signature IS the step contract:
ComplianceResult check(String content);2. Retry with Exponential Backoff
Model APIs fail. Rate limits happen, usually at the worst possible moment – like when you’re doing a batch run at 2 AM before a big launch. Spring Retry handles this cleanly.
// Add to pom.xml:
// <dependency>
// <groupId>org.springframework.retry</groupId>
// <artifactId>spring-retry</artifactId>
// </dependency>
// Add @EnableRetry to PipelineConfig, then annotate service methods:
@Retryable(
retryFor = {RuntimeException.class},
maxAttempts = 3,
backoff = @Backoff(delay = 1000, multiplier = 2.0)
)
public ComplianceResult checkWithRetry(String draft) {
return complianceChecker.check(draft);
}3. Structured Output with Validation
LangChain4j deserializes model output into Java records via Jackson. Models occasionally produce malformed JSON – fail fast and clearly, not mysteriously downstream.
// Add jakarta.validation constraints directly to result records:
public record ComplianceResult(
@NotNull List<String> violations,
@Pattern(regexp = "none|minor|major|critical") String severity
) {}
// Validate after each AI service call:
Validator validator = Validation.buildDefaultValidatorFactory().getValidator();
Set<ConstraintViolation<ComplianceResult>> issues = validator.validate(result);
if (!issues.isEmpty()) {
throw new IllegalStateException("Invalid AI response: " + issues);
}4. Step-Level Observability
Log every step: what went in, what came out, how long it took. You will need this. I promise you will need this. The one time you skip it is the one time something goes wrong at 3 AM and you have nothing to go on.
// StepTimer.java — lightweight timing wrapper
@Component
public class StepTimer {
public <T> T time(String stepName, Supplier<T> step) {
long start = System.currentTimeMillis();
T result = step.get();
System.out.printf("[STEP] %s completed in %dms%n",
stepName, System.currentTimeMillis() - start);
return result;
}
}
// Usage in ContentPipelineService:
ClassificationResult classification =
stepTimer.time("classify", () -> classifier.classify(draft));5. Idempotency Keys
If you’re processing at scale, failures will happen and you’ll retry runs. Use Spring’s @Cacheable to make steps safe to re-run with the same input – no double-processing, no duplicate editorial briefs.
// Add @EnableCaching to PipelineConfig, then:
@Cacheable(value = "compliance-results", key = "#contentHash")
public ComplianceResult checkCached(String contentHash, String draft) {
return complianceChecker.check(draft);
}
// Generate the cache key from content:
String hash = DigestUtils.md5DigestAsHex(draft.getBytes(StandardCharsets.UTF_8));
ComplianceResult result = checkCached(hash, draft);The Workflow Mindset
A workflow is a factory floor. Each station does one defined job. The conveyor belt – your orchestrator – moves material between stations in the order you designed. Quality control happens at specific checkpoints. Defects get routed to rework, not back into the main flow.
You are the factory architect. The AI is the skilled worker at each station. The worker is good at their specific job – classifying, scoring, summarizing, extracting – but they don’t redesign the assembly line. That’s your job.
Here’s what makes this mental model useful: factory architects don’t ask the press operator what kind of factory they should build. They figure out the process first, then staff the stations. Same principle. Figure out your process – draw the flowchart, write the routing logic, define the outputs – then add AI at the stations where human judgment would normally sit.
Don’t let the AI drive. Let it work.
We’ve covered the agent (AI decides what to do) and the workflow (you decide what to do, AI handles each step). Both are more powerful when they’re built on a solid foundation of reusable capabilities – which is what Part 3 is about.
Skills are the atomic building blocks: self-contained, typed, testable capabilities that plug into agents as tools or into workflows as steps. Getting this layer right is what separates a 1-off prototype from a system you can actually maintain and extend. It’s also the part most people skip, to their eventual regret.